从 Checkpoint 平均,到 Task Expert 合并,再到专家蒸馏
一篇关于「模型合并」的综述笔记:从训练轨迹上的 checkpoint 平均,到共享 base 的 task expert 合并,再到生产级多专家蒸馏。| 2026-06
问题引入
Rio 事件是一个直接的切入点:2026 年 6 月,IplanRIO 发布的 Rio 3.5 Open(397B)随后被发现,其核心做法不过是对 Nex-N2-Pro 与 Qwen3.5 做线性权重插值。值得关注的不是模型归属,而是它暴露出的事实——模型权重可以直接做线性合并,而且结果未必会坏。
这件事背后有两个值得单独讨论的问题:
- 为什么权重空间中的简单运算能够成立;
- 当手里已经有多个同源模型版本时,是否能够把它们进一步合并为一个”更好的”统一模型。
本文按三类对象展开这一问题:Part 1 关注训练轨迹上的 checkpoint merging;Part 2 关注共享同一 source model 的 task expert 合并;Part 3 关注训练更重的多专家场景,以及从权重合并转向蒸馏的原因。
整体框架
本文按三类合并对象展开:
| 阶段 | 合并对象 | 适用条件 | 对应方法 |
|---|---|---|---|
| Part 1 | 同一次训练里的 checkpoint | 同轨迹,条件最干净 | averaging |
| Part 2 | 同 base 分叉的 task expert | 同源但已分叉,开始出现干扰 | task arithmetic,model merging |
| Part 3 | 生产级 SFT/RL expert | 训练更重,权重合并开始失稳 | 蒸馏,把专家的分布合回一个模型 |
一句话总结:关键不在”平均”这个动作本身,而在这些模型是不是还处在同一片可连通的低损失区域里。对象越近,这件事越容易成立;训练越重、分叉越远,就越要从合权重转向合行为。
Part 1:训练轨迹上的 checkpoint 合并
Preliminary: Loss Landscape 基本概念
要理解”为什么权重能平均”,先得有一套描述 loss 地形的语言。把参数空间想象成一片高低起伏的地貌,训练就是从某处出发往低处走的过程。后面整篇文章反复用到的,其实就是下面三个地形概念。
第一是 sharp / local minima——尖峰式的窄坑。 坑底很低,但四壁陡峭,稍微偏一点 loss 就飙升,模型很难稳定停留,泛化通常也差。
第二是 wide / flat basin——宽而平的盆地。 这是我们想要的地形:底部平坦,权重小幅扰动 loss 几乎不变,对应更好的泛化。大模型在充分训练后往往自然落进这种宽 basin,这也是后面一切平均操作能成立的物理基础。(一句严谨补充:“平坦 → 泛化好”是经验相关而非已证因果——SWA 作者本人也把增益主要归于 train/test loss 曲面的错位,且 sharpness 的定义可被重参数化改写。)
第三是 barrier——两个 minima 之间隆起的山脊。 它是判断”能不能直接平均”的关键:如果两个解之间隔着 barrier,把它们的权重线性插值就要翻越这道山脊,中间点 loss 飙高、模型直接崩坏;反之如果它们落在同一个连通的 basin 里、中间没有 barrier,平均才安全。整篇文章的主线,某种意义上就是在反复追问”这两个模型之间到底有没有 barrier”。
早期相关工作
权重平均不是新东西,它的史前史至少能追到上世纪。这里把四篇奠基性的老工作串一下,它们各自答对了问题的一角,但都还没有”共享预训练起点”这个后来才出现的关键概念。
最早是 Utans 19961:在集成学习盛行的年代,他第一次把多个网络的权重直接加起来取平均,发现居然有效——但当时没人认真对待这条线索。十几年后 Goodfellow 20142 给了一个朴素却重要的观察:沿”初始化 → 最终权重”这条直线插值,loss 大体平滑单调下降,说明训练走的并不是一条坑坑洼洼的路。要注意它插的是零初始化到终点,而不是后续工作那种”同源多次训练得到的不同解之间”插值——这个区别后面会变得很关键。
真正把权重平均变成实用技巧的是 SWA 20183。它的洞察是:用较高学习率跑 SGD 时,动力学会让权重停在一个宽 basin 的边缘来回震荡,而不是落到中心;那么只要沿训练轨迹把这些解等权平均一下,就能把解推回 basin 中心那片更宽更平、泛化更好的区域。好用,但”为什么能这么平均”在这个时代还没讲清楚。
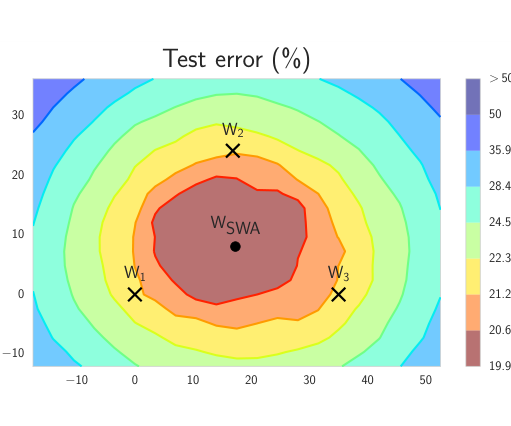
SWA:三个 SGD 解 (×)停在 basin 边缘,等权平均得到的 (●)落入中心更宽更平的低 test-error 区域
同年的 Mode Connectivity / FGE 20184 则换了个角度看 loss 地形:两个独立训练得到的 minima,用直线插值确实要翻越中间的高 loss 山脊(barrier),但存在一条曲线能把它们在低 loss 区域内无 barrier 地连起来。这说明 loss 地形里的”谷”远比想象中连通。很经典,但在 Adam 主导、又没有大规模预训练的时代,它的实用性还比较有限。
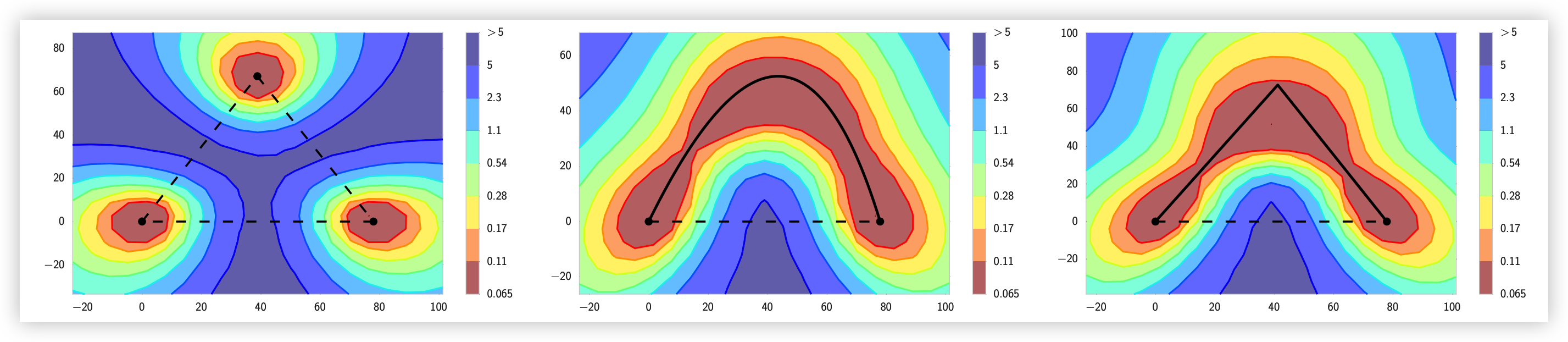
Mode Connectivity:独立 minima 之间直线插值(虚线)要穿过高 loss 山脊,但存在一条曲线路径(实线)始终待在低 loss(暖色)区域内把它们连起来
这几篇工作有一个共同的时代局限:那时还没有真正的大规模 pre-training 概念,实验规模都很小,对”多个模型共享同一个预训练起点”意味着什么,还没有清晰的认识。而这恰恰是下一节 LMC 要补上的那块地基。
LMC 与共享 basin 条件
这是整条主线的地基。 前面几篇都在讲单条轨迹或独立训练,真正把”共享起点”这件事钉死的是 LMC。问题可以这样问:两个独立从零训练的模型之间有 barrier,那如果两个模型共享了某个中间 checkpoint、再各自分叉训练呢?LMC(Frankle 20205,Lottery Ticket 作者的 follow-up)的发现是:只要两条轨迹共享一个足够靠后的中间节点,再把两条轨迹末端的权重做线性插值,中间点的 loss 不再隆起、近乎单调——barrier 消失了;而完全独立的两次训练之间,barrier 依然存在。注意”足够靠后”这个限定:稳定性不是从初始化就有的,而是训练早期跑过一小段之后才出现。
它的意义有两层。第一,这是”权重平均可用”的几何前提——共享起点让两个解大概率落在同一片连通的低损失区域里,平均才不会踩到 barrier。第二,它顺带解释了为什么大规模预训练之后再各自微调、然后合并会特别有效(这正是 Part 2 的基础)。需要诚实地补一句:LMC 严格证的只是”同任务、仅 SGD 噪声不同”这一最干净的情形,而 Model Soups 那种”合并不同任务的微调模型”是更强的经验外推;后来的 permutation 对齐工作(如 Git Re-Basin)还表明,即便不共享起点,把神经元先对齐也能消除 barrier——也就是说”共享起点”是个充分但非必要的条件。但它足够干净、足够实用,所以后面几乎所有工作都默认在这个条件下运作。
LAWA 与 Early-WA
既然共享起点就落在同一个 basin,自然想到:不等训练完再平均,训练途中就把最近 k 个 checkpoint 平均,直接跳到更靠前的位置。LAWA 20226 取最新 k 个 checkpoint 等权平均,训练中段就能跳前;k 太大(>16)反而掉点——把还在移动的早期权重拉进来了。Early-WA × High LR 20237 解耦采样间距与 k,推到 LLM 预训练,并给出关键观察:checkpoint 平均 ≈ post-hoc 学习率退火的替身——高 LR 让 AdamW 在高曲率方向震荡,平均抹平震荡、保留进展。两篇合起来 claim:averaging 不只是泛化增强,它实际能在训练中替代一部分退火的作用。
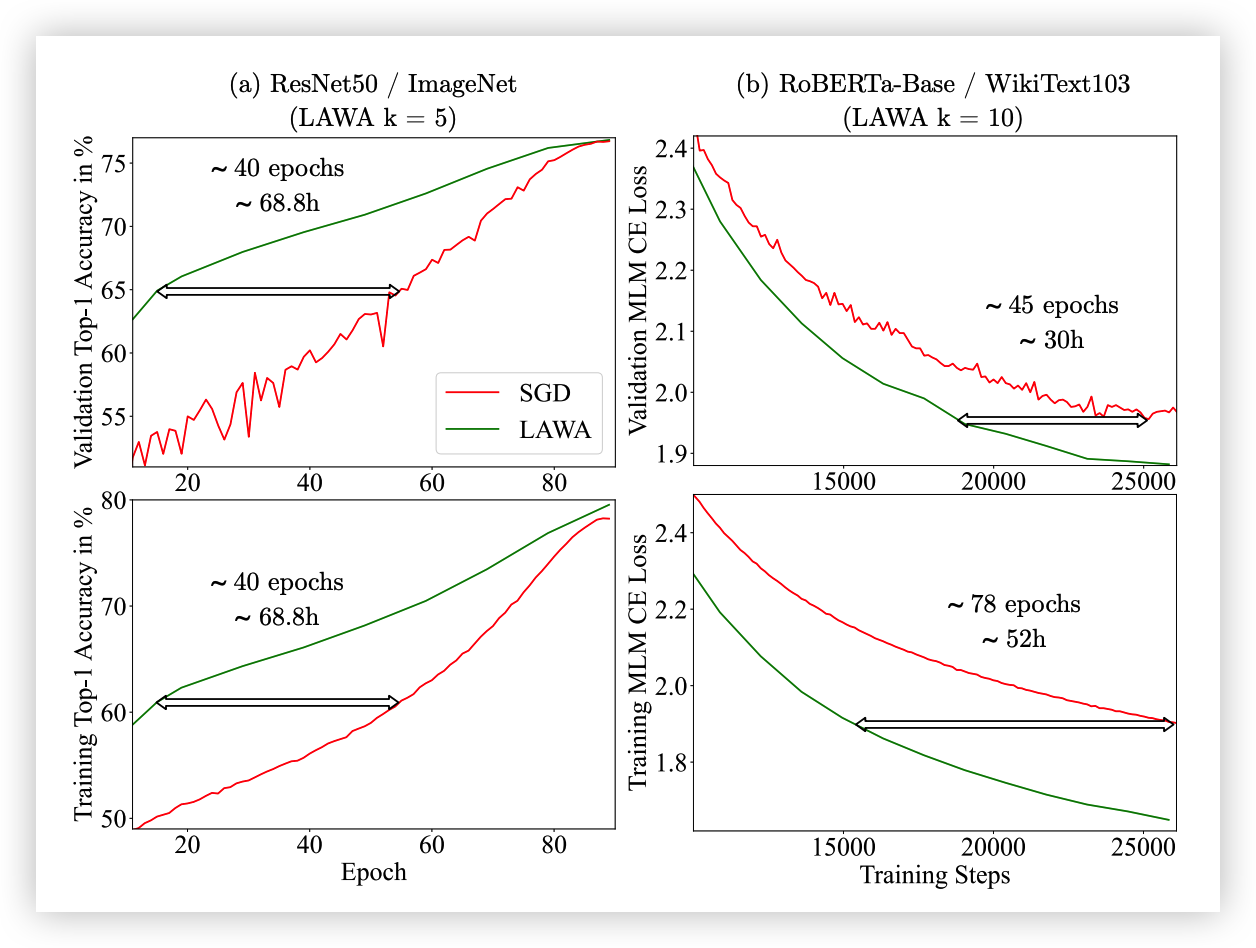
LAWA:在 ResNet50 / ImageNet(k=5)与 RoBERTa-Base / WikiText103(k=10)上,对最近 k 个 checkpoint 等权平均(绿线)都比基线 SGD(红线)提前数十 epoch 达到同等精度 / loss——相当于训练中段直接跳到更靠前的位置
贝叶斯优化与合并系数搜索
百川智能在预训练里认真用了 checkpoint merging。Checkpoint Merging via Bayesian Optimization(Liu 20248)把合并约束为成对合并 ,一维搜索就够,再用贝叶斯优化在小留出集上几次评测锁定最优 。合并系数第一次从”拍脑袋”变成”被搜出来的”。结论略显符合直觉:λ 越偏向最新权重越好。部分结论只在成对合并这个 setting 下鲁棒,但它把”成对合并 + 系数搜索”这个 pattern 固定了下来。
PMA:用合并替代退火
背景是 MiniCPM 提出的 WSD(Warmup–Stable–Decay) 预训练范式:训练分 Warmup → 恒定 LR 的 Stable → 最后 Decay(退火)三段,而退火段成本不低。PMA(Pre-trained Model Average,字节跳动 20259)给出三条核心发现:
- PMA-init:用平均后的权重作为下一阶段训练的初始点,训练更稳;
- PMA 可以代替完整的退火过程:在 Stable 段定期合并,效果 match 甚至超过完整退火,>100B 规模下坐实;
- 超参规律:合并间隔与模型规模相关,合并策略(等权 / EMA)的差异基本可忽略。
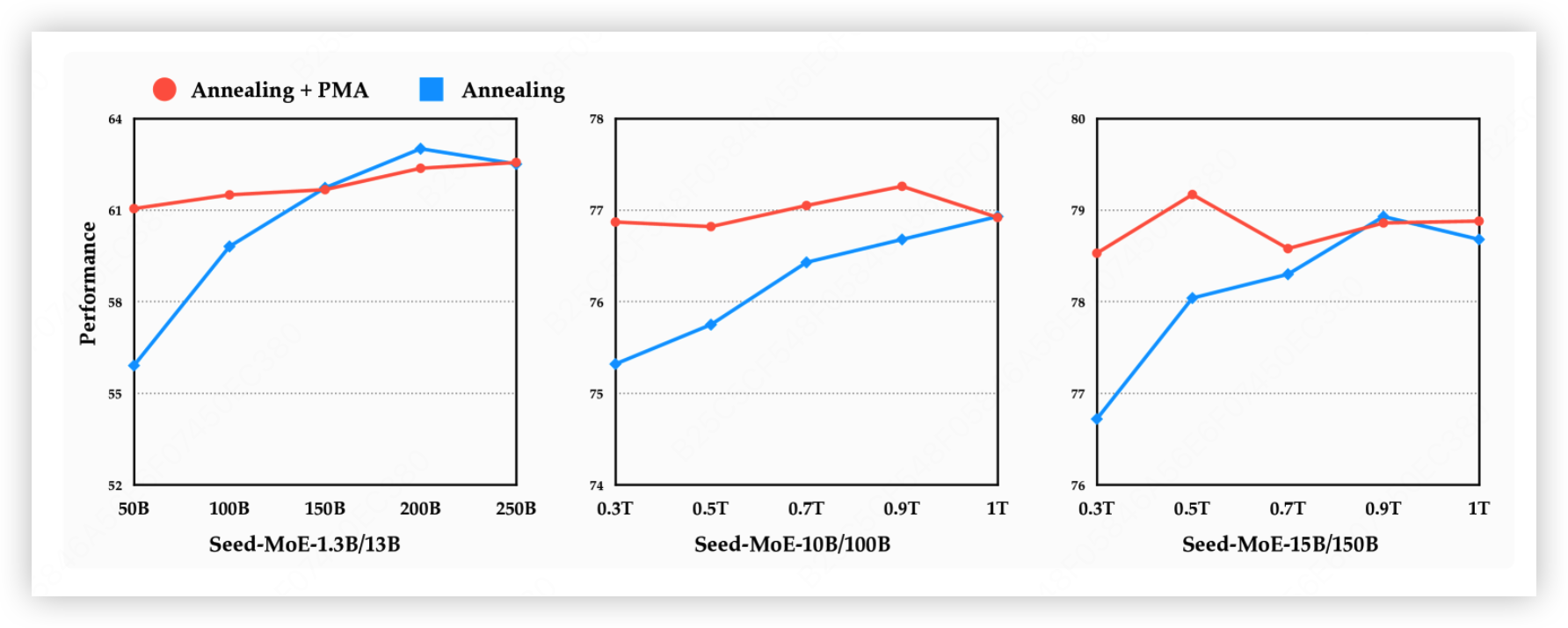
规模验证覆盖 dense 411M–70B、MoE 到 200B。这说明权重的线性运算不是小规模偶然成立的技巧,而是可以成为工业训练流程的一部分。不过要诚实标一个边界:PMA 的增益更像是 Stable 段的阶段性隐式集成——一旦进入 continued training,合并模型基本会收敛回 baseline,SFT 上的增益也零星不稳。所以它真正的价值在”训练中段替代退火 + 预测退火后质量”,而不是让模型永久变强。
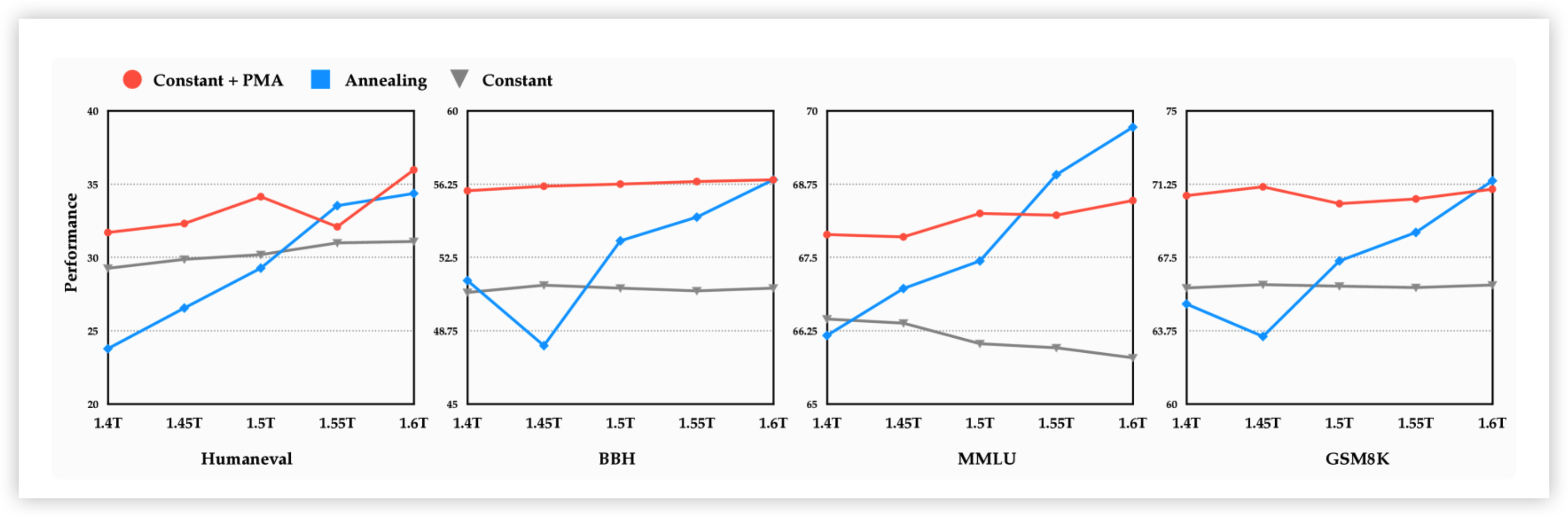
PMA 训练出来的 benchmark 的性能
PMA vs. 完整退火的 loss 对比
WSM:学习率衰减与合并等价
WSM(Warmup–Stable–Merge,202510)问了更理论的问题:decay 和 merging 是不是同一件事?答案是数学上等价——LR decay 本质是对每步梯度施加递减权重,merging checkpoint 也是。于是”怎么 decay”可以翻译成”怎么分配合并权重”,反过来”怎么合并”也给出一种新的 decay 设计方式。关键发现:merge duration(覆盖的 token 窗口)比 checkpoint 数量和间隔更重要。PMA 的目标是 match 退火,WSM 的目标是超越退火,且可无缝续训。
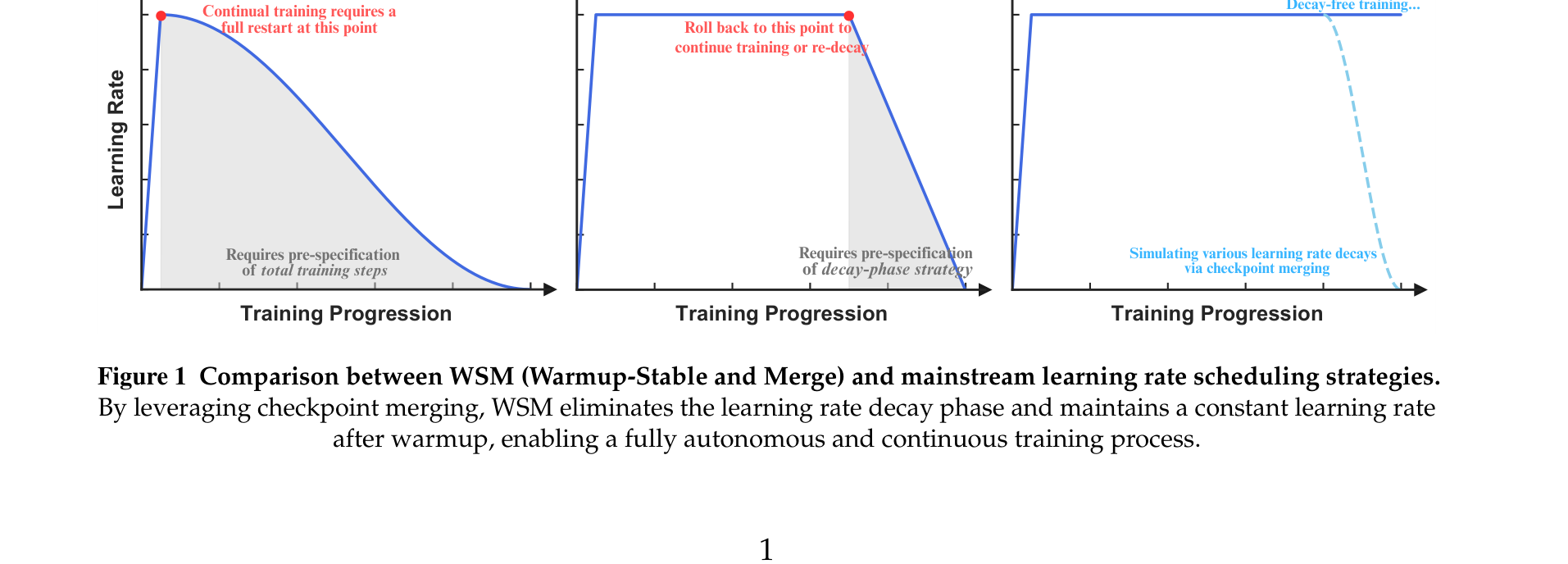
WSM:LR 调度与合并权重的对应
Extra-Merge 与 rank-1 外推
到这里,合并一直是”凸包内插值”——在已有点之间取平均。Extra-Merge(202611)问了更激进的问题:合并之后的轨迹是什么形状,能不能往外走一步?
核心洞察是:退火阶段的更新方向非常线性。原始 checkpoint 在 loss 地形里横跳(山壁方向的高频震荡),方向杂乱、高维;一旦做滑动平均,横向抖动被消掉,所有合并点塌缩到”沿河前进”的那条线上。PCA 验证:相邻已合并点之间插值严格单调下降,merged 轨迹第一主成分解释 >94% 方差——这条线就是 rank-1 子空间。
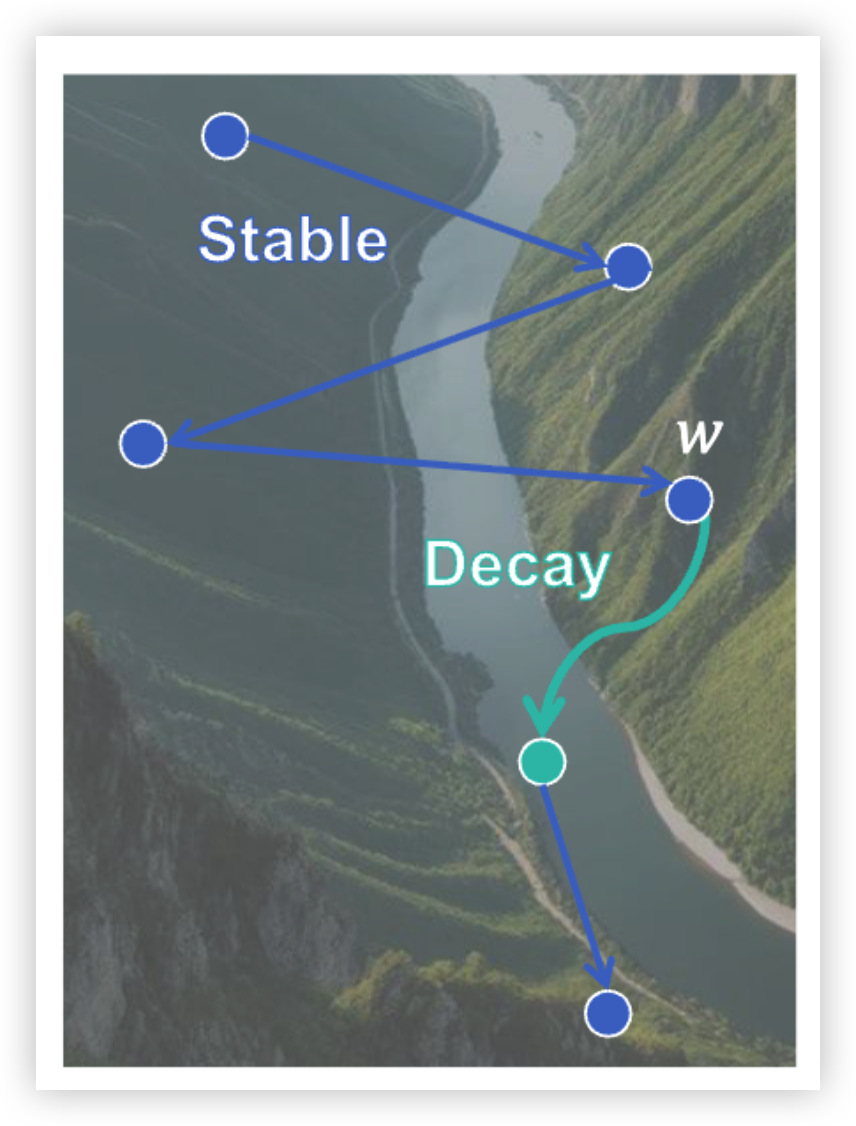
river-valley 河谷地形示意
换句话说:滑动平均滤掉山壁横跳后,这几个已合并 checkpoint 的相邻变化量几乎全指向同一方向(rank-1 主成分),所以不必再依赖梯度,直接沿这一主方向走即可。既然合并点排成一条朝下坡的直线,那就别停在最后一个点,沿这条线再外推一步:,免梯度更新就把 loss 推得更低。方法是 PCA 取第一主成分定方向、自适应贪婪外推、验证 loss 回升即停;GPT-2 / LLaMA / Pythia-12B 全规模成立。一句话总结:平均 = 几何低通滤波器,滤掉山壁噪声、留下河流方向,而这个方向线性到可以外推。
Takeaways
- 条件:共享预训练起点 = 共 basin = 可以合并(LMC 建立这个前提);
- 应用:平均能加速收敛、替代退火,且 LR decay ≡ merging(LAWA / Early-WA → PMA → WSM);
- 外推:退火轨迹是 rank-1,可以从内插走到外推(Extra-Merge)。
到目前为止合并的都是同一次 run 里的 checkpoint。如果是同一个 base 出发、但走向不同任务方向的 expert——还能合吗?这个问题的第一个实验答案是 Model Soups,也是 Part 2 的起点。
Part 2:Task Arithmetic 与多任务权重合并
共享同一 base 的多个微调模型起点处于同一 loss basin,其 delta 可以像向量一样加减来组合能力。
Task Vector 定义
把微调前后的权重差定义为任务向量:
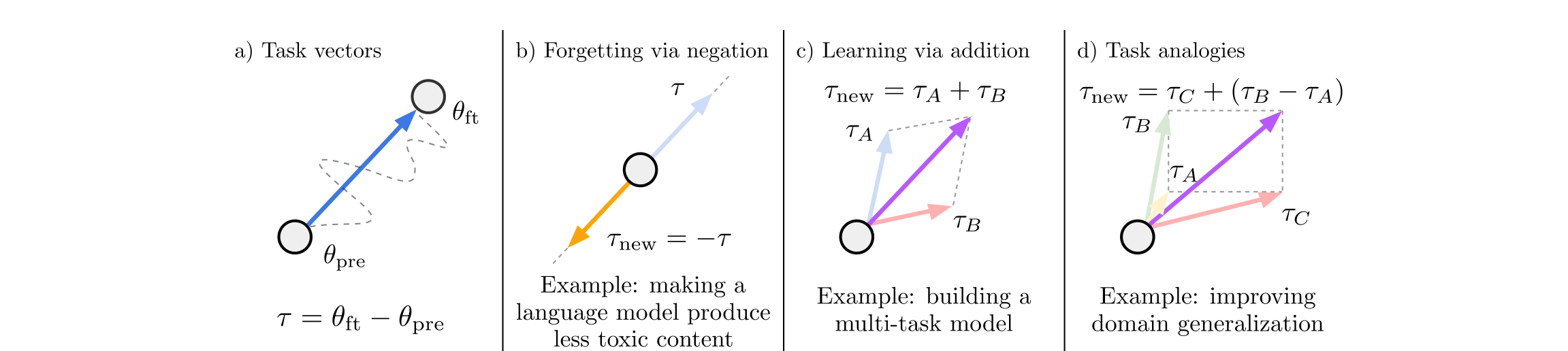
Task Arithmetic:任务向量 可像向量一样运算——取负 选择性遗忘某能力,相加 组合多任务,类比 做跨任务迁移
加 获得某项能力(代码、多语言、数学……),减 选择性遗忘某项能力,多个 相加就是多任务无训练合并。后面所有合并方法,本质都是以不同方式处理 task vector。
从模型平均到 task vector 加减
Model Soups 是实验起点:同一初始化、只是超参不同的微调模型直接权重平均就涨点,推理时零额外开销——成立的前提还是共享同一预训练 anchor、落在同一个 basin。Task Arithmetic 是概念枢纽:把上面所有操作统一成 task vector 的加减,甚至支持类比式的 。整条主线的语言统一于此。
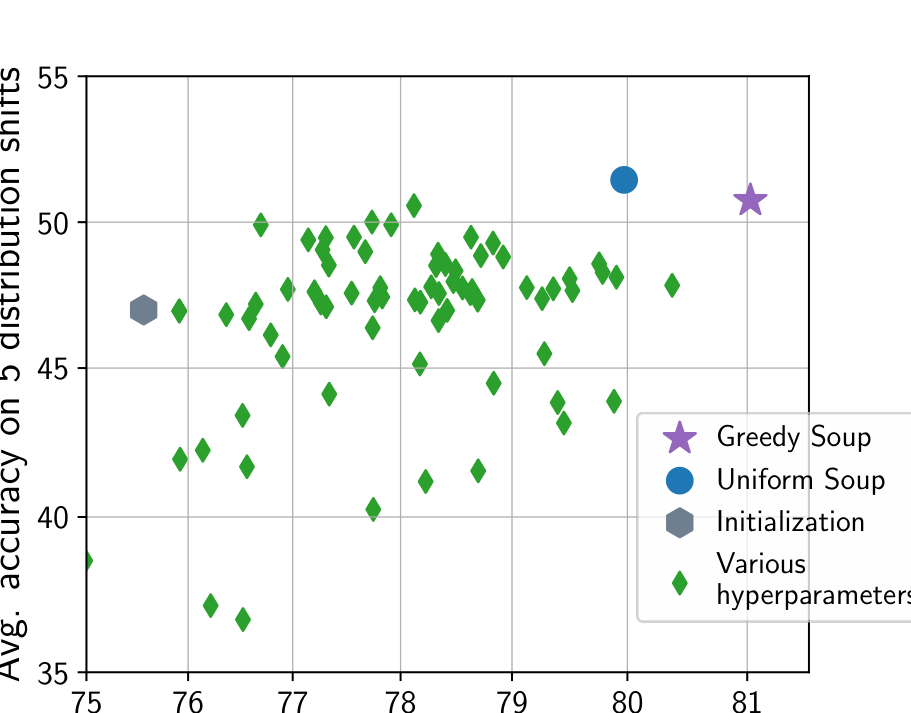
Model Soups:每个绿点是一组不同超参的单个微调模型;对它们做权重平均得到的 Greedy Soup(紫星)/ Uniform Soup(蓝点)在 ImageNet 准确率与 5 个分布偏移的平均准确率上同时超过所有单模型与初始化点(灰六边形)
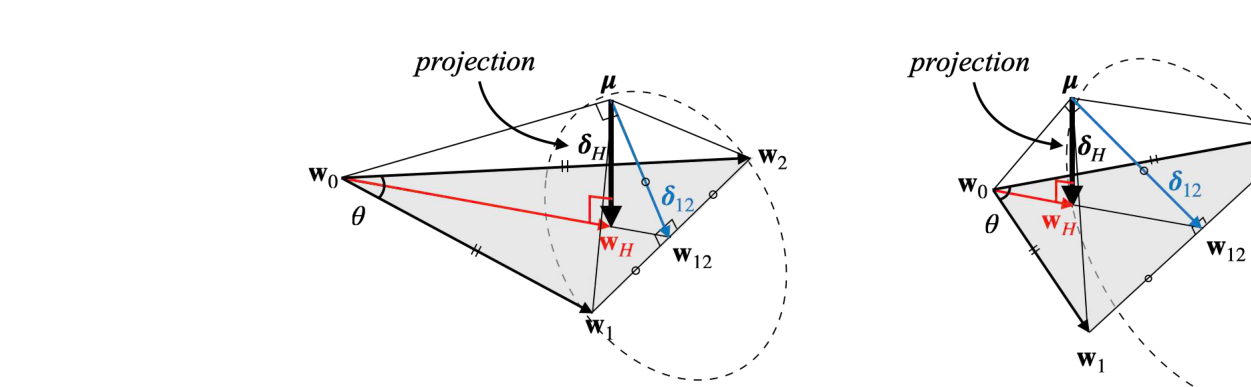
Model Stock:微调权重 与预训练点 的几何关系——二者张角 决定了最优插值位置 (锚点 在 平面上的投影),因此只需极少几个微调模型就能逼近权重中心
干扰问题与稀疏化方法
多个 相加会互相干扰——既有冗余参数,也有符号冲突。TIES 用三步处理:Trim(只留 top-k 幅度,去冗余)→ Elect Sign(多数票定方向,解符号冲突)→ Merge(只平均同号项,消除不一致平均)。三步里真正起决定作用的是 Elect Sign——消融显示单独做 Trim 几乎不涨点,符号选举才是 TIES 远比朴素相加更抗”任务数增长”的关键。DARE / Super Mario 更暴力——随机丢掉 90%–99% 的 delta,存活项乘 补回期望,性能几乎不掉,说明 SFT delta 高度冗余、大部分是噪声;它是即插即用的预处理,可挂在任何合并法前面。不过 DARE 有个硬前提:delta 必须足够小(典型纯 SFT,幅度约 ≤0.002);一旦 base 经过持续预训练、delta 变大(例如 WizardCoder 从 CodeLlama 续训而来),哪怕只丢 10% 也会灾难性崩坏。DELLA 则是 TIES + DARE 的合体。
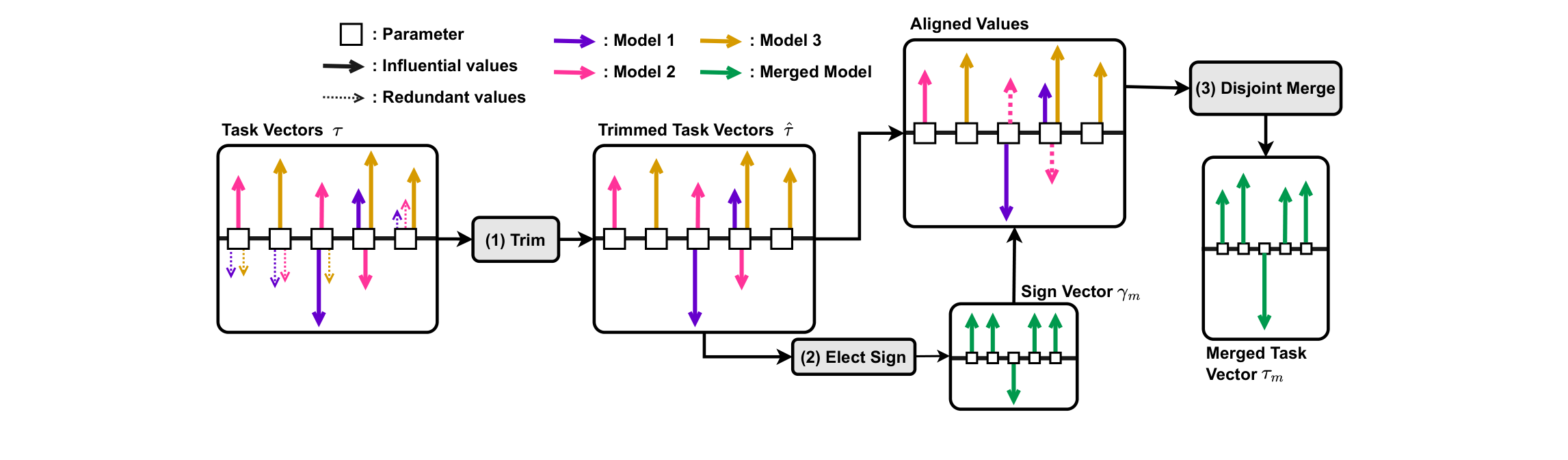
TIES 三步:(1) Trim 只保留幅度 top-k 的参数以去冗余 →(2) Elect Sign 按多数票为每个参数选定符号以解符号冲突 →(3) Disjoint Merge 只平均与选定符号一致的项,避免正负相消
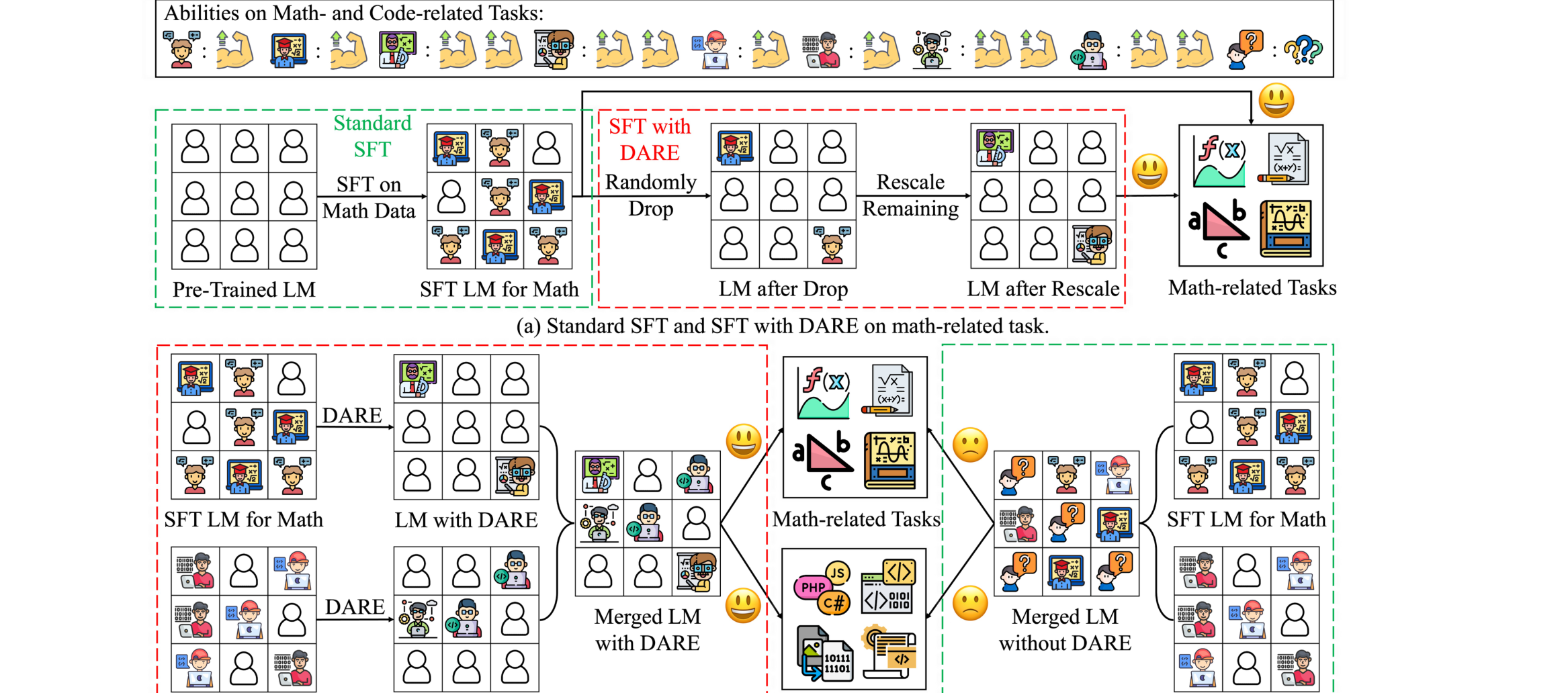
DARE:对 SFT delta 随机丢弃大比例参数,再对存活项按 重缩放以保持期望——(a) 单模型 drop 90%+ 后性能几乎不掉,说明 SFT delta 高度冗余;(b) 作为预处理挂在任何合并法前面,可显著减少多模型合并时的参数干扰
可学习与可搜索的合并方法
上面全是手工规则,自然要问:能不能把合并本身变成可优化问题?AdaMerging 用熵最小化在无标注测试集上学出逐层的合并系数;EvoMerge(Sakana AI)用进化算法同时搜参数空间(混合系数)和数据流空间(层怎么堆),发现人类想不到的跨域组合;DRM 先 SVD 投到联合空间、重归一化再做 TIES,相当于”换对坐标系再合”,恰好呼应 Extra-Merge 的 rank-1 子空间。合并已从”经验技巧”走向”可优化、可搜索、可换空间”的方法论。

AdaMerging:从手工固定系数(b/c:Task Arithmetic 与 Task-wise)走向 (d) Layer-wise——为每一层、每个任务向量学一个独立的合并系数 ,用无标注测试集上的熵最小化来求解这些系数
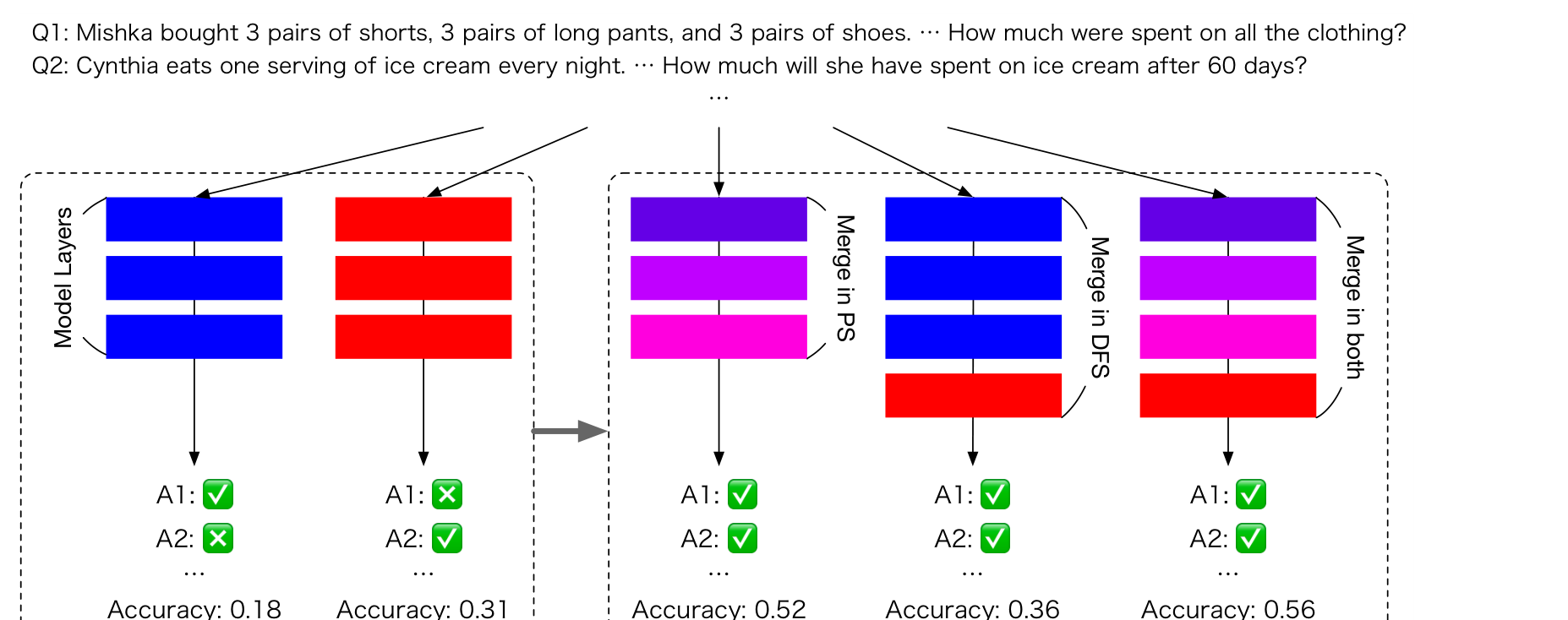
EvoMerge:用进化算法同时在参数空间(PS,模型权重的混合系数)与数据流空间(DFS,各层的堆叠与路由)搜索合并配方;下方 Accuracy 显示 Merge in PS / DFS / both 都超过两个源模型(0.18、0.31),both 最高(0.56)
task vector 的几何解释与后训练性质
先说为什么 task arithmetic 能成立。 核心前提是:微调后的权重仍停留在预训练点附近的近线性区域,没跑远。Ortiz-Jiménez 等人把背后的真正机制命名为 weight disentanglement(权重解耦)——权重空间里不同的方向,控制着函数空间里相互分离、各自局部的功能区域,所以把不同任务的 task vector 叠加起来时,它们各管各的,不容易互相打架12。有意思的是,作者明确反对”task arithmetic 只是 NTK / 线性化近似的副产品”这种解释——解耦是比”局部线性”更强的性质;切空间里的线性化微调之所以有用,是因为它会进一步放大这种解耦结构,而不是因为它更”线性”。(顺带澄清一个常见误读:把它想成”不同任务对应近正交方向”是个方便的直觉,但 task vector 之间并不真的正交,这也不是论文的论证。)
那么后训练到底改动了多少权重? 答案往往比直觉小得多,而且结构很特别。RL 实测常常只更新 5%–30% 的参数子网络,单独把这块子网络拎出来训练,就能接近复现整模型的效果——而且这种稀疏更新在秩上反而接近满秩,并不低秩13。(更准确地说,驱动这种稀疏的并不是”RL”这个标签,而是 on-policy / in-distribution 训练本身——in-distribution 的 rejection-sampling SFT 同样稀疏,而 off-policy 的 DPO 反而是稠密更新。)从谱的角度看更精细:RLVR 几乎不动预训练模型的主奇异方向,奇异值谱也与 base 高度接近,更新被系统性地导向那些非主成分、低曲率的方向14。SFT 那侧则是另一种”小”:delta 高度冗余,随机丢掉 90% 以上仍几乎不掉点25;更早还有工作用内在维度解释微调为何只需在极少数方向上发力15。
这里有几个容易混淆、必须分开看的区分:更新量小 ≠ 能力没变,稀疏 ≠ 低秩,低维 ≠ 稀疏。 RL 的更新可以在参数上很稀疏,却仍接近满秩13;而内在维度刻画的是一个低维子空间15,那是 SFT 一侧的低秩故事——两者不是一回事。还有个反直觉的提醒:14 某种程度上拆穿了”RL 就是稀疏”的简单读法——它论证那种表观稀疏很大程度是 bf16 精度下的假象,真正的机制是更新落进了 off-principal 子空间,而非真有大片参数纹丝不动。
延展:从”小扰动”到”激发还是注入”
把行为侧和权重侧的证据拼在一起,会指向一个更大、但也更需要小心的判断:后训练或许更像是在释放预训练模型里已有的能力,而不是从零注入全新的能力。 行为侧的证据是:随着 pass@k 增大,base 模型可以反超 RLVR 模型,说明那些推理路径原本就躺在 base 的采样分布里,RL 更多是把它们采样得更高效16。权重侧的证据就是上面那些:参数改动整体小而结构化,更像在已有结构附近做局部重排。
但这个”激发而非注入”的论断远未盖棺定论,它是这条线里争议最大的一层。最干净的反例是 ProRL24:当 RL 训得足够久、足够稳(KL 控制、reference policy 重置、多样任务),RL 模型能在很宽的 pass@k 范围内、甚至在 base 怎么采都做不出来的题上超过 base——也就是边界被真正扩张了。所以更诚实的说法是:在当前主流、相对短的 RLVR setup 下,RL 主要是 sharpen 而非 expand;而”够久够稳的 RL 到底能不能扩边界”仍是 open question,分歧很大程度落在训练时长、稳定化技巧、以及 pass@k 这个度量本身上。把两侧证据当作互相支持的线索就好,别急着当成因果结论。
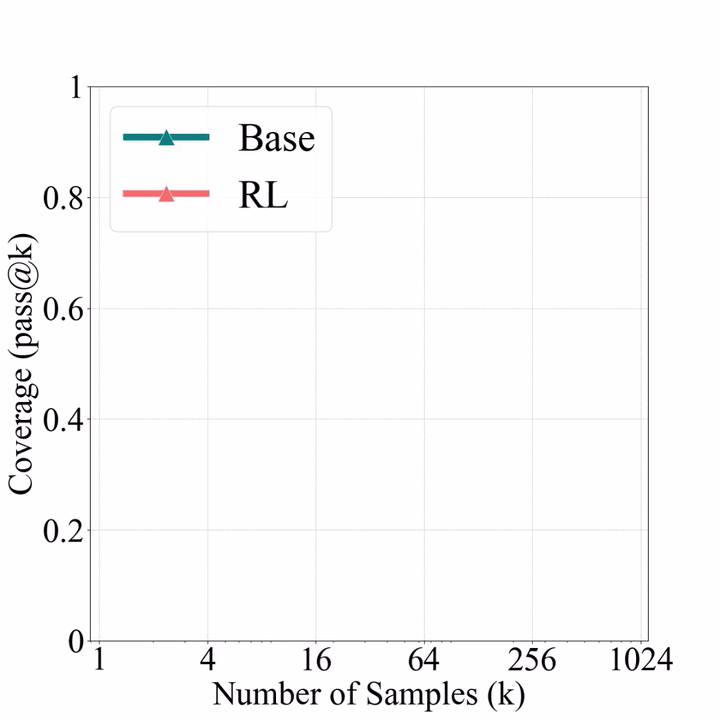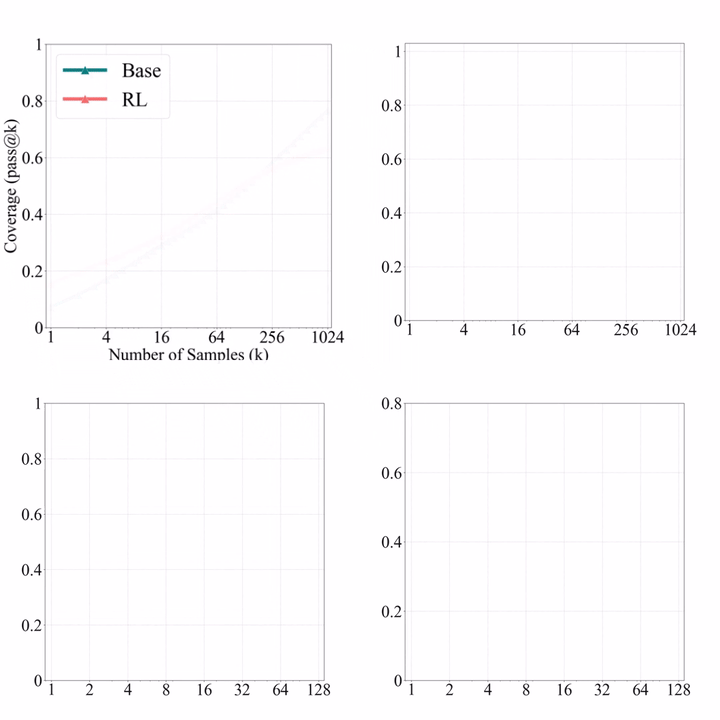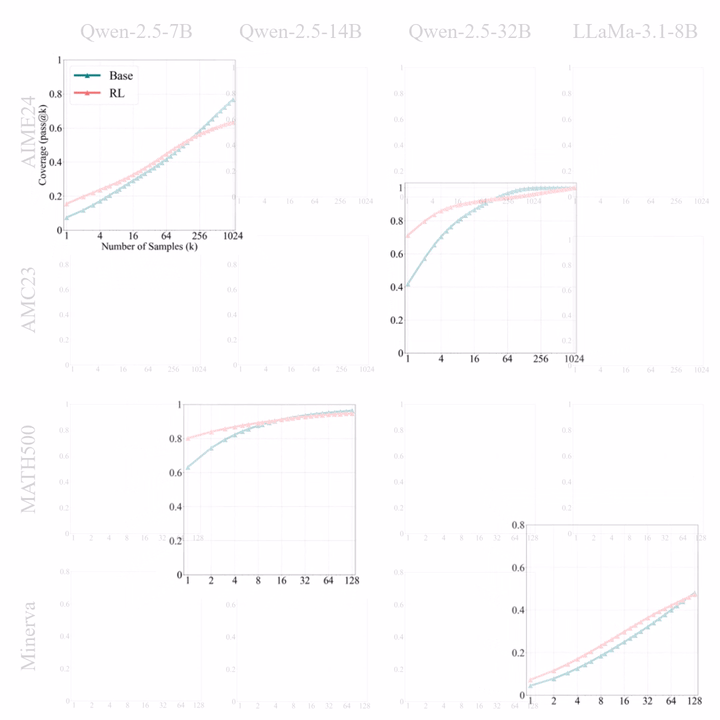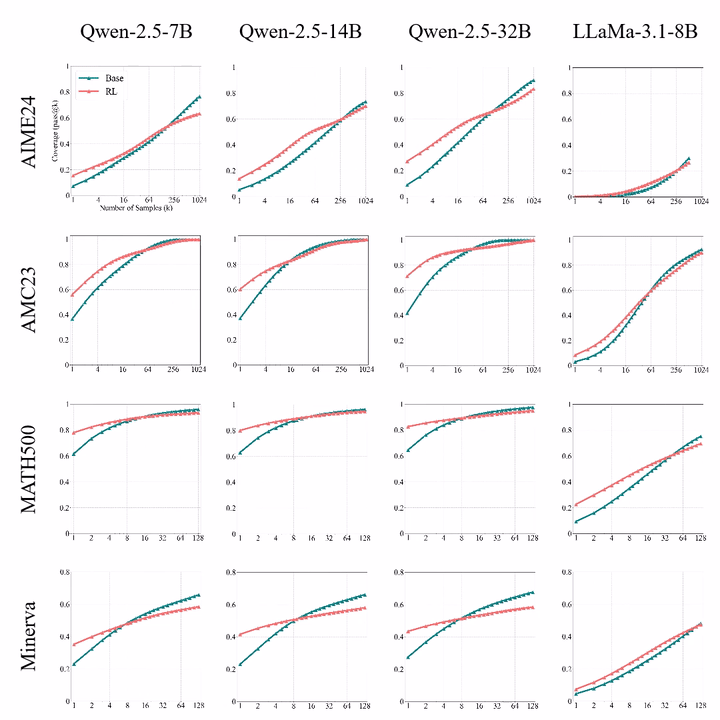
经典论文:Does RL Really Incentivize Reasoning Capacity? NeurIPS 25 best-paper runner-up
如果把”能力就藏在预训练点附近”这个图景再往前推一步,会看到一个更极端的证据:有些工作甚至完全不依赖梯度更新。Neural Thickets / RandOpt17 直接在预训练权重附近撒高斯扰动,筛出表现好的候选再做集成,在相同训练算力(FLOPs)下就能接近甚至超过 PPO / GRPO。不过有两点要按住、不要 overclaim:其一,论文给的是行为层面的拆分而非真正的机制探针——在 GSM8K 上,提升里约 12% 来自真实的推理修正、约 19% 来自答案格式的纠正,作者自己也讲”部分而非全部增益来自格式对齐”,并没有做激活 / 注意力级的因果分析;其二,所谓”同算力”只算训练 FLOPs,推理时要跑 K(≈50)次前向,开销反而更大,并非免费午餐。但即便打了这些折扣,结论依然有力:专家能力可以在预训练点的邻域里被采样出来。这也顺势引向 Part 3——如果专家能力本就密集分布在预训练点附近、可被采样或激发,那么当权重几何不再可靠时,真正值得保留的,就更可能是专家的行为分布,而不是它的权重本身。
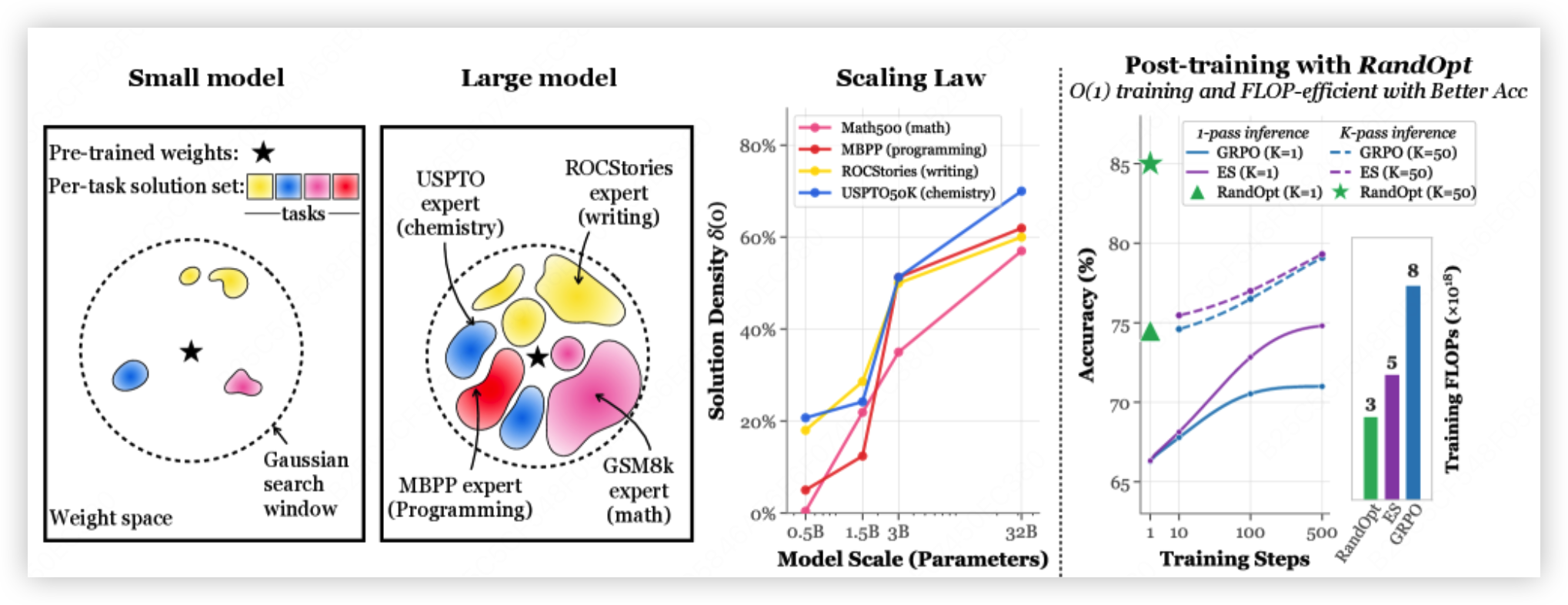
RandOpt:在预训练权重邻域随机扰动、筛选、集成,也能”捞”出任务专家
参数空间合并的边界
上面这些前提——delta 小、近线性、方向趋同——在生产级 RL 专家身上都不成立了。Part 2 的一切成立条件是温和微调、δθ 小、同 base、几何还在;而生产级 RL 专家经历大规模 RL、domain-specific 奖励信号差异极大,delta 漂移大、噪声异构,直接平均权重开始掉点甚至打坏性能。那该怎么合?大厂的选择是:不合权重,合行为——合的是专家生成的数据和 logit。
Takeaways
- task vector 可以加减,但要处理干扰(TIES 三步 / DARE 随机剪 / 自动搜系数);
- 后训练是小扰动,激发而非学习——SFT/RL 选数据别指望注入真正的新知识,要激发模型已有的能力;
- 几何的边界:delta 越大、血缘越远、奖励异构性越高 → 权重几何越不可靠。
Part 3:多专家蒸馏合并
到了生产级 RL 专家这一层,前两部分赖以成立的权重几何已经退化:delta 漂移大、噪声异构,直接在参数空间里平均会掉点甚至打坏模型。于是这一部分的主角从”合权重”换成了”合行为”——退出参数空间,转而在输出分布层面对齐,也就是蒸馏。
多领域 RL 专家的合并问题
数学专家 + 代码专家 + Agent 专家 + 写作专家 + 逻辑专家,各自在各自的奖励下训到峰值,现在要合回一个。合权重试过,掉点——delta 漂移大、噪声异构,直接平均会坏;合数据(蒸馏)则让专家各自 rollout 生成轨迹,在干净 base 上 SFT 合回去。
分叉训练与蒸馏回收范式
为什么分叉:数学 verifier、代码 test-pass、Agent 任务成功率——奖励信号差异极大,混训梯度互相干扰,谁也训不到峰值;分叉颗粒度取决于奖励信号会不会打架,不是领域名字像不像。为什么不合权重:RL 后专家 delta 漂移大,in-weights 合并的几何前提已失效。为什么蒸馏有效:专家生成的数据 / logit 在行为空间整合,没有参数冲突。范式骨架就是:同源 base/SFT → 分叉 N 个域专家(各自 RL)→ 蒸馏合回单一 student。
离线蒸馏路线
同源 base → 多个域专家各自 RL(奖励因域而异:规则 verifier / 编译 + test case / 任务成功率)→ rollout → 数据合并 → 在 base 上 SFT(self-distillation)→ 最后一轮统一混合 RL 兜底(防多阶段能力退步)。这套结构18 已被 Step 3.5 Flash、Qwen3-Coder19 反复验证,是当前行业共识。需要诚实地补一句:这些工业报告几乎都没做隔离 ablation(“蒸馏那一步单独贡献多少”、“蒸馏 vs 合权重同条件对比”都没给),所以”student 继承了各专家能力”更多是工程经验而非被实证的机制归因。但这只影响机制层面的解释,并不动摇真正的结论——在大规模异构沙箱 + 大公司组织架构下(Code 这类专门优化需要独立的资源与沙箱,硬混训只会拉长整体 bubble),分叉 + 蒸馏是合理且近乎必然的工程选择。Qwen3-Coder 的延伸:coding 内部还要再分 WebDev / SWE / QA / UX 四个专家——再次印证分叉颗粒度取决于奖励信号打不打架,不取决于领域名字像不像。
在线蒸馏路线
在线蒸馏的内核很简单:让 student 自己 rollout,teacher 针对 student 当前的输出给 token 级信号,哪里偏纠哪里。相比离线”先攒数据再 SFT”,on-policy 的好处是信号更密、收敛更快、遗忘更少。下面三家的做法分别代表了串行、并行、级联补丁三种思路。
GLM-5(串行 · On-Policy Cross-Stage Distillation)20:后训练按能力依赖拆成三个串行阶段(Reasoning → Agentic → General)。串行的代价是灾难性遗忘,解法是把前一阶段最终 checkpoint 当 teacher,在 student 自己的 rollout 上做在线蒸馏——把 GRPO 的 advantage 换成 teacher / student 的 token 级 log-prob 比值(stop-gradient),哪里偏在哪里纠,贯穿全程。
- 为什么串行:Agent 建立在 Reasoning 之上,三类目标混训梯度互相干扰,按依赖顺序串行专精更干净。
- Teacher = 前一阶段最终 checkpoint(自蒸馏,同架构,零兼容成本);prompt 从各阶段训练集按比例混采,覆盖全部旧能力。
- 与 GLM-4.5 的演化:GLM-4.5 训完后做一次离线大蒸馏;GLM-5 改为贯穿 RL 全程的持续在线锚定——同样叫”蒸馏”,从一次性变成了持续。
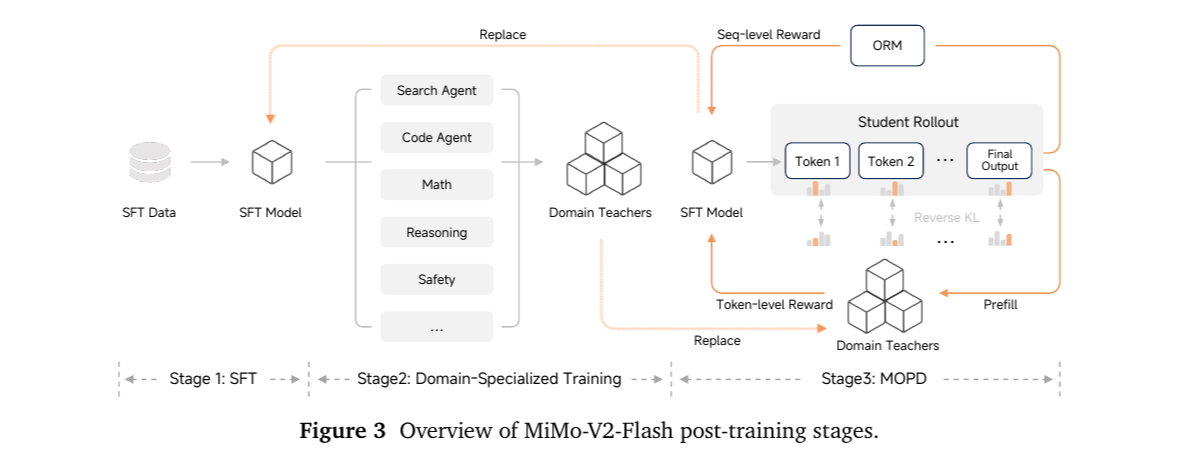
MiMo-V2-Flash / MOPD(并行 · Multi-Teacher On-Policy Distillation)21:把蒸馏和 RL 合成一个阶段同时跑。Student rollout 后,按 prompt 的 domain 路由到对应 teacher,teacher 在每个 token 位置给反向 KL 监督,作为 token 级 dense advantage 塞进 GRPO,再与 ORM 结果奖励线性相加。
- 比传统 KD loss 灵活:teacher 信号是 advantage 的一项,可与 ORM、可验证奖励任意组合。
- 比联合多域 RL 稳定:按 domain 路由,每个 teacher 只管自己域的 prompt,梯度不再跨域冲突,收敛更快。
- ⚠️ 关键坑:student 走出 teacher 不熟悉却正确的路径时,teacher 给误导信号——BrowseComp 回退 6.3 分(MOPD 后 45.4 vs 最强 teacher 51.7)。Teacher 的认知边界会成为 student 的天花板。
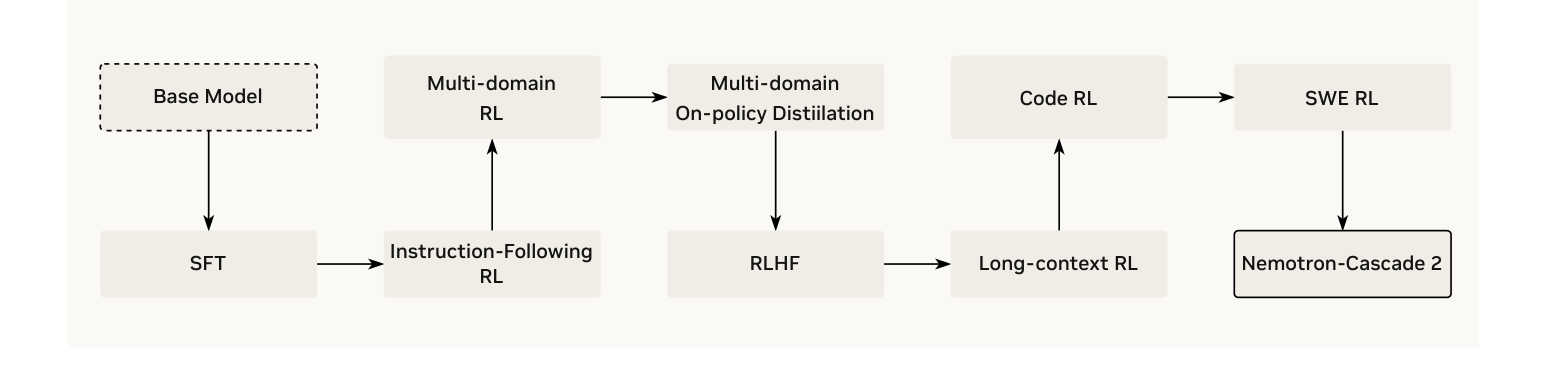
Nemotron-Cascade-2(顺序级联 + MOPD 再平衡)22:7 阶段顺序级联跑完会出现明显能力漂移(RLVR 压低数学推理多样性、RLHF 部分牺牲指令遵循),在漂移点之后插一段 MOPD 补救——用 3 个固定 domain teacher(Math = 初始 SFT checkpoint、RLHF = RLHF 后 checkpoint、Multi-domain = 多域 RL 后 checkpoint)把漂掉的能力拉回。
- 插法是”补丁”而非贯穿:MOPD 在漂移点之后定向补救,不是全程在线——与 GLM-5 的持续锚定思路不同。
- 收敛效率:token 级 dense advantage 远比 sparse sequence reward 快——AIME25 上 MOPD 30 步到 92.0,GRPO 25 步才 91.0;ArenaHard 上 MOPD 52 步到 85.5,RLHF 需 160 步才到 80.7。
- 命名坑:MiMo 与 Nemotron 都称自己的方法为 MOPD,机制相近,大概率同期独立命名。
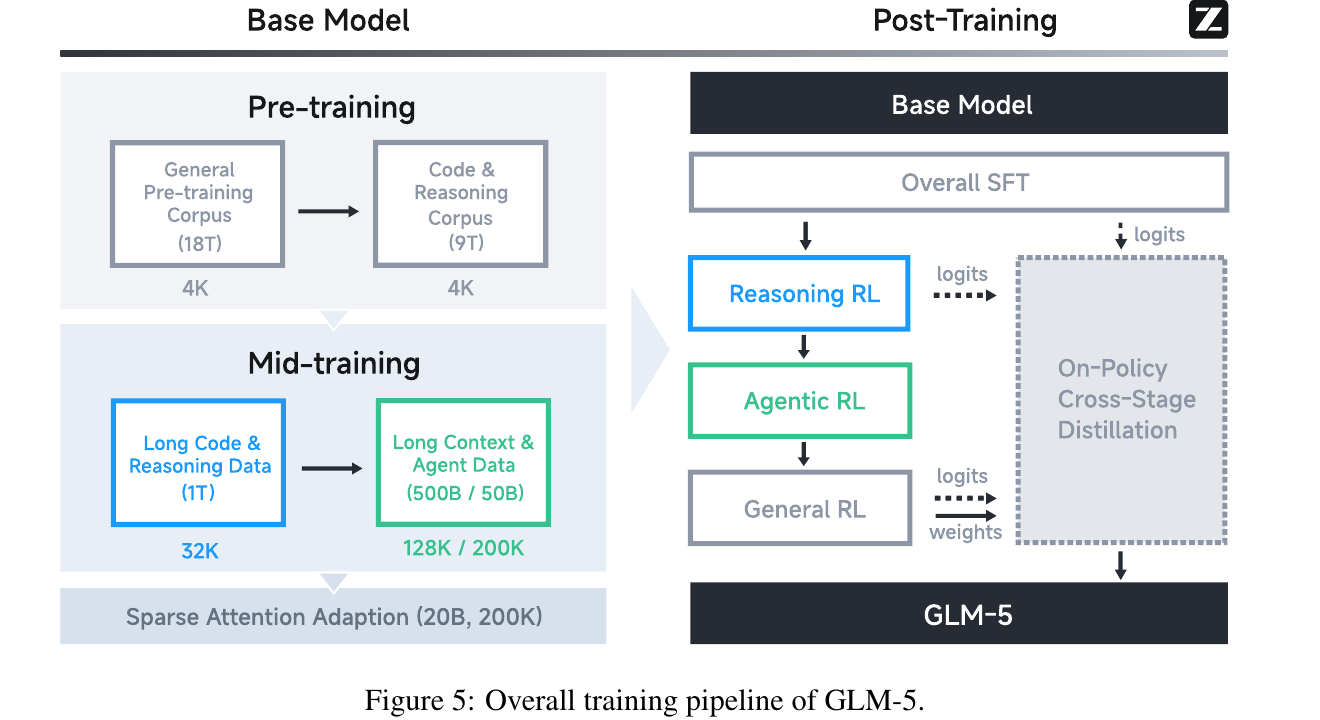
GLM-5:三阶段串行 + 跨阶段在线蒸馏锚住旧能力
MiMo-V2-Flash / MOPD:teacher logits 作为 dense token 级 reward 注入
Nemotron-Cascade-2:7 阶段顺序级联 + 中间 MOPD 再平衡
M2RL:混训、分叉与几何重叠
头号结论23:Qwen3-4B-Base,五域(Math / Code / Science / IF / Agent),混合多任务只用 63.7% GPU·h 就追平”分叉 + 最优合并(TIES-Merging)“。大厂选分叉,是因为奖励 / 超参 / 基础设施的工程隔离价值——不是因为指标碾压混训。
域交互有结构(不是乱打架):推理三域(Math / Code / Science)是互惠家族——训一个,另两个也跟着涨;IF(指令跟随)单向帮推理,推理不帮 IF;Agent 是孤岛——既不影响别人也不被别人影响,不产生干扰,这是优点。
几何缝合——接回 Part 2 主线:多域 RL 专家之间 Jaccard mask 重叠 0.45–0.48(随机 mask 基线只有 0.18),且重叠区 cosine 为正。说明它们也落在高度重叠的参数子空间、方向趋同 → 合并是加成的,不是相消的。这是 Part 2”同 basin、几何对齐”直觉在生产级 RL 专家上的实测证据,也是全场几何主线的最终收束。
最终,weight merging 主要是继承专家能力——增益一致、稳定可预测;而混训 / 蒸馏能涌现出单专家没学到的新能力,但鲁棒性差(过程验证 process verification 会崩)。稳但只继承,vs 能涌现但要付鲁棒性代价——这正是”该混还是该合”没有唯一答案的根源。
但这个结论得打一个很大的折扣——它的外部效度存疑。 M2RL 的全部对照都建立在”干净”的学术 benchmark 之上:五个边界清晰、信号纯净、规模可控的域。而真实工业生产里的一个 domain,背后往往是极其庞大且严格异构的沙箱集合——环境之间彼此不兼容、奖励口径各异、规模大上几个数量级,信号里裹挟的噪声也大得多。“低干扰、混训就够”这个判断,在五个干净域上成立,未必能迁移到这种大规模、强异构、高噪声的真实场景;恰恰是在后者,分叉所提供的工程隔离(奖励、超参、基础设施各自独立)才显出不可替代的价值。所以单看指标,这篇 paper 的说服力是被”benchmark 太干净”削弱了的。不过——它真正值钱的不是那个具体数字,而是它敢于 rethink”分叉到底是不是必要的”这个被默认成共识的前提,并给出了域交互有结构、可量化的证据。这种对 convention 的追问,本身非常值得学。
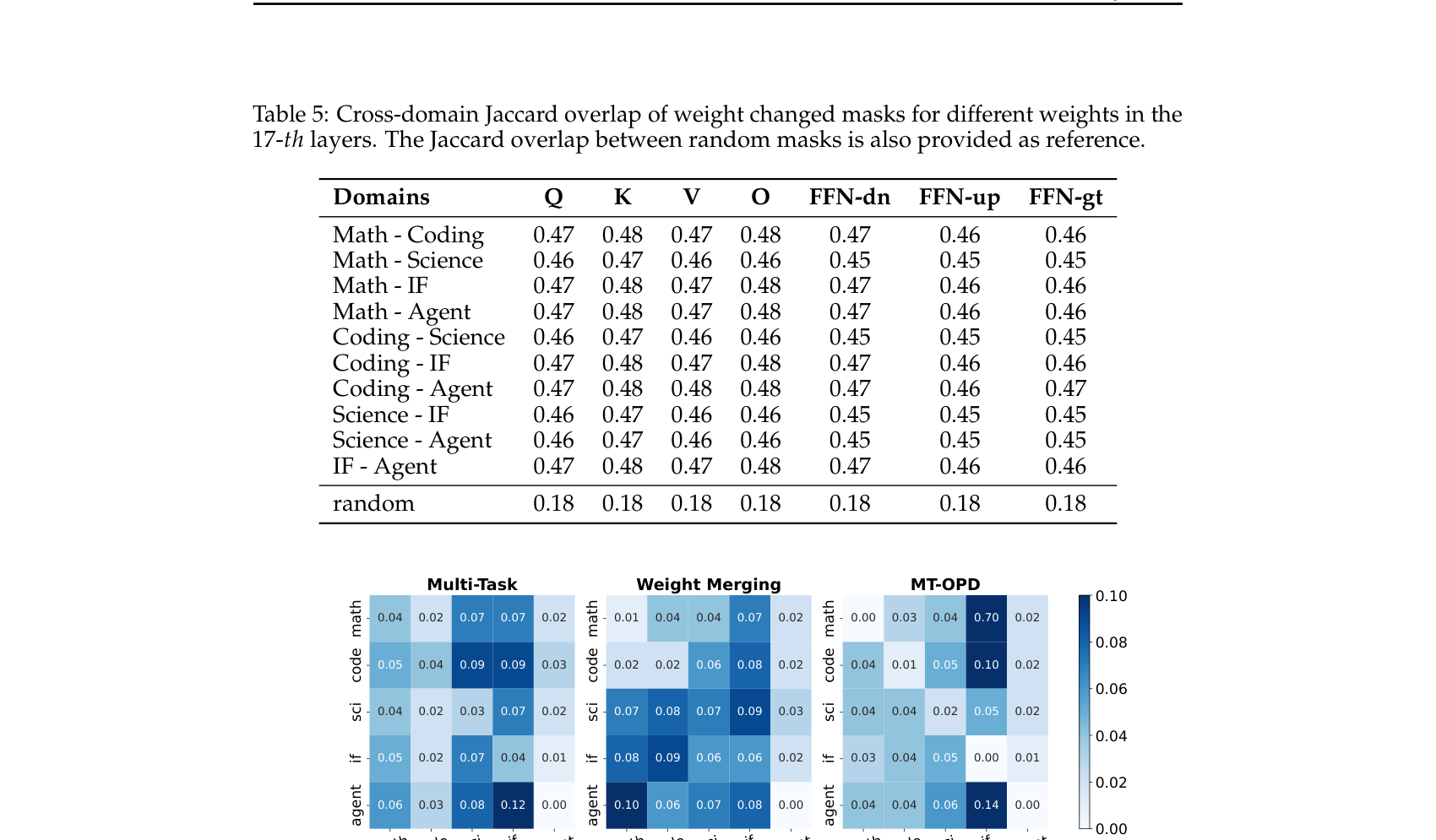
M2RL:多域 RL 专家 Jaccard mask 重叠 0.45–0.48,远高于随机基线
Takeaways
- 参数空间合并的边界:RL 专家 delta 漂移越大 → 越该转向蒸馏;合数据比合权重更抗干扰;
- 在线蒸馏 > 离线蒸馏:on-policy 信号密、防遗忘;但 teacher 在 student 的新路径上会给误导信号(MiMo 的 BrowseComp 坑);
- M2RL 的实用建议:算力紧张先试混训;分叉的价值在工程隔离,不在指标。
总结:三类合并方法的统一视角
回到开头那张表,现在每一格都有了具体含义:
| 阶段 | 合并对象 | 适用条件 | 对应方法 |
|---|---|---|---|
| Part 1 | 同轨迹 checkpoint | 同 basin,最干净 | 外推、替代 annealing |
| Part 2 | 同 base task expert | 几何还在,被 interference 绷紧 | 加减、稀疏化、搜索 |
| Part 3 | 生产级 RL expert | 退化,退出参数空间 | 蒸馏,合行为不合权重 |
一句话:血缘越远、后训练越重 → 几何越不可靠 → 越被逼着从参数空间退到函数空间。
工程启示
- 预训练 / 持续预训练:checkpoint 不是废料;PMA-init 让续训更稳;预训练点邻域比想象中密(随机扰动就能捞到专家)。
- SFT:delta 高度稀疏冗余——合并前先试 DARE 丢掉 90%;SFT 是激发,别指望注入真正的新知识。
- RL / RLVR:专家只动了 5–30% 子网络,多域 RL 专家落在重叠子空间、方向趋同,可以合;但漂移大了就转蒸馏。
- Agentic RL:Agent 是孤岛是优点——不产生干扰;MOPD 里 teacher 会在 student 的新路径上给误导信号(BrowseComp 那个坑),注意。
开放问题
- 河在多大尺度上会弯掉? Extra-Merge 增益只有亚个百分点、靠早停兜底——rank-1 是局部性质;真正大规模长训练上,PMA 的 decay-skipping 和 Extra-Merge 的外推都在押这个赌注,但没人系统测过。
- 合权重 vs. 合数据的边界到底在哪? M2RL 说 63.7% 算力混训就够,那 Part 2 的合并在什么情形下真有优势?算力约束、数据可得性、实验隔离需求——还没有干净答案。
最后一句 Charge:整条线都在用 uniform 平均——主干(SWA → PMA → WSM → Extra-Merge)默认 SMA 因为简单,而旁支的贝叶斯搜权重、EvoMerge 进化搜配方、SoCE 非均匀合并独立模型在 task vector 场景一直更强。没人把”非均匀加权”搬回单轨迹合并——这个正交方向还空着,可能是下一个非增量方向。
延伸:顺着 Part 1「checkpoint 轨迹携带几何信息」这条线,我写了一份 proposal——Update-Anchored Post-Training,把训练轨迹里的更新方向当作后训练的可复用锚点。
引用
- Utans, J. Weight Averaging for Neural Networks and Local Resampling Schemes. AAAI Workshop, 1996.
- Goodfellow, I., Vinyals, O., Saxe, A. Qualitatively Characterizing Neural Network Optimization Problems. ICLR 2015. arXiv:1412.6544, 2014.
- Izmailov, P., Podoprikhin, D., Garipov, T., Vetrov, D., Wilson, A. G. Averaging Weights Leads to Wider Optima and Better Generalization (SWA). UAI 2018. arXiv:1803.05407, 2018.
- Garipov, T., Izmailov, P., Podoprikhin, D., Vetrov, D., Wilson, A. G. Loss Surfaces, Mode Connectivity, and Fast Ensembling of DNNs (FGE). NeurIPS 2018. arXiv:1802.10026, 2018.
- Frankle, J., Dziugaite, G. K., Roy, D. M., Carbin, M. Linear Mode Connectivity and the Lottery Ticket Hypothesis. ICML 2020. arXiv:1912.05671, 2019.
- Kaddour, J. Stop Wasting My Time! Saving Days of ImageNet and BERT Training with Latest Weight Averaging (LAWA). NeurIPS 2022 Workshop. arXiv:2209.14981, 2022.
- Sanyal, S., Neerkaje, A., Kaddour, J., Kumar, A., Sanghavi, S. Early Weight Averaging meets High Learning Rates for LLM Pre-training. arXiv:2306.03241, 2023.
- Liu, D., et al. Checkpoint Merging via Bayesian Optimization in LLM Pretraining. arXiv:2403.19390, 2024.
- ByteDance Seed. Model Merging in Pre-training of Large Language Models (PMA). arXiv:2505.12082, 2025.
- Yang, et al. WSM: Warmup-Stable and Merge — Decay-Free Learning Rate Schedule via Checkpoint Merging. arXiv:2507.17634, 2025.
- Zhou, W., Wang, B., Zhang, H., Jia, C., Chen, W., Cheng, X. Tracing the Rank-1 Subspace of Model Merging in Language Model Pre-Training. ICML 2026. arXiv:2605.26484, 2026.
- Ortiz-Jiménez, G., Favero, A., Frossard, P. Task Arithmetic in the Tangent Space: Improved Editing of Pre-Trained Models. NeurIPS 2023. arXiv:2305.12827, 2023.
- Mukherjee, S., Yuan, L., Hakkani-Tür, D., Peng, H. Reinforcement Learning Finetunes Small Subnetworks in Large Language Models. arXiv:2505.11711, 2025.
- Zhu, H., et al. The Path Not Taken: RLVR Provably Learns Off the Principals. NeurIPS 2025 ER Workshop. arXiv:2511.08567, 2025.
- Aghajanyan, A., Zettlemoyer, L., Gupta, S. Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning. ACL 2021. arXiv:2012.13255, 2020.
- Yue, Y., Chen, Z., Lu, R., Zhao, A., Wang, Z., Song, S., Huang, G. Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? NeurIPS 2025 Oral. arXiv:2504.13837, 2025.
- Gan, Y., Isola, P. Neural Thickets: Diverse Task Experts Are Dense Around Pretrained Weights. arXiv:2603.12228, 2026.
- DeepSeek-AI. DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models. arXiv:2512.02556, 2025.
- Qwen Team. Qwen3-Coder-Next Technical Report. arXiv:2603.00729, 2026.
- Zhipu AI (GLM Team). GLM-5: from Vibe Coding to Agentic Engineering. arXiv:2602.15763, 2026.
- Xiaomi LLM-Core Team. MiMo-V2-Flash Technical Report. arXiv:2601.02780, 2026.
- NVIDIA Nemotron Team. Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation. arXiv:2603.19220, 2026.
- Wang, H., Long, X., Li, Z., Xu, Y., Li, T., Tang, Y. To Mix or To Merge: Toward Multi-Domain Reinforcement Learning for Large Language Models. arXiv:2602.12566, 2026.
- Liu, M., et al. (NVIDIA). ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models. arXiv:2505.24864, 2025.
- Yu, L., Yu, B., Yu, H., Huang, F., Li, Y. Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch (DARE). ICML 2024. arXiv:2311.03099, 2023.